
DeepSeek-Coder-V2: Przełamanie bariery modeli zamkniętych w inteligencji kodu
1. Wprowadzenie
Przedstawiamy DeepSeek-Coder-V2, otwartoźródłowy model językowy do kodowania oparty na architekturze Mixture-of-Experts (MoE), który osiąga wydajność porównywalną z GPT-4 Turbo w zadaniach związanych z programowaniem. DeepSeek-Coder-V2 został dodatkowo przetrenowany na podstawie pośredniego punktu kontrolnego DeepSeek-V2, wykorzystując 6 miliardów dodatkowych tokenów. Dzięki temu dalszemu szkoleniu model znacząco poprawia swoje zdolności w zakresie kodowania oraz matematycznego rozumowania, jednocześnie zachowując wysoką skuteczność w zadaniach językowych.
W porównaniu do DeepSeek-Coder-33B, wersja V2 wykazuje znaczący postęp w różnych aspektach zadań związanych z kodowaniem, rozumowaniem oraz ogólną wydajnością. Dodatkowo rozszerza obsługę języków programowania z 86 do 338, a długość kontekstu zwiększa się z 16K do 128K.
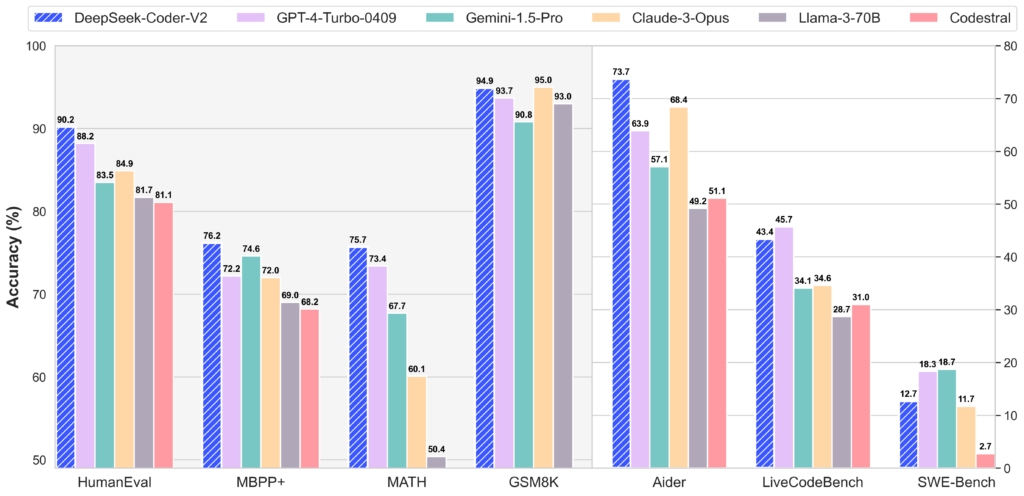
W standardowych testach porównawczych DeepSeek-Coder-V2 przewyższa modele zamknięte, takie jak GPT-4 Turbo, Claude 3 Opus oraz Gemini 1.5 Pro, w benchmarkach kodowania i matematyki.