
DeepSeek-V2: Potężny, ekonomiczny i wydajny model językowy Mixture-of-Experts
1. Wprowadzenie
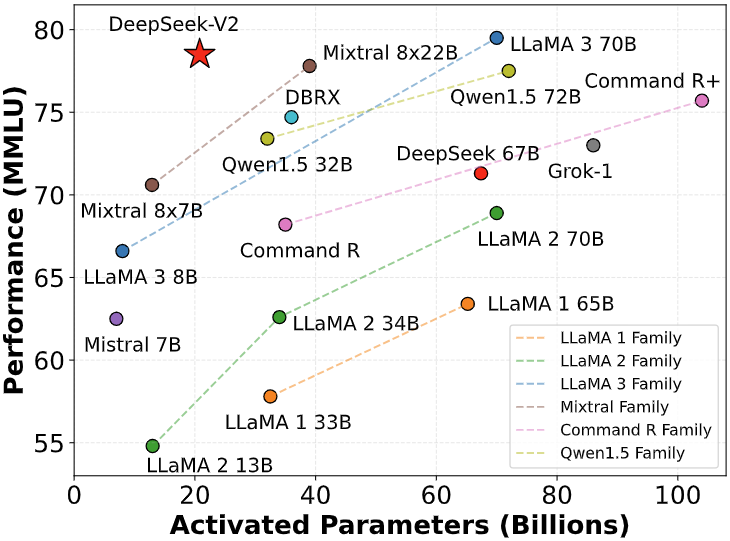
Przedstawiamy DeepSeek-V2, zaawansowany model językowy oparty na architekturze Mixture-of-Experts (MoE), który wyróżnia się ekonomicznym procesem szkolenia i wydajnym wnioskowaniem. Model składa się z 236 miliardów parametrów, z których 21 miliardów jest aktywowanych dla każdego tokena.
W porównaniu do DeepSeek 67B, DeepSeek-V2 oferuje:
- Wyższą wydajność
- Oszczędność 42,5% kosztów szkolenia
- Redukcję pamięci podręcznej KV o 93,3%
- Zwiększoną przepustowość generacji maksymalnie o 5,76 razy
Model został wstępnie przetrenowany na 8,1 bilionach wysokiej jakości tokenów z różnorodnych źródeł. Po tym etapie przeprowadzono Supervised Fine-Tuning (SFT) oraz Reinforcement Learning (RL), aby w pełni wykorzystać jego możliwości.
Wyniki ewaluacji potwierdzają skuteczność zastosowanego podejścia – DeepSeek-V2 osiąga znakomite rezultaty zarówno w standardowych benchmarkach, jak i w zadaniach związanych z generacją otwartą.
2. Aktualności
- 16 maja 2024 – Premiera DeepSeek-V2-Lite.
- 6 maja 2024 – Premiera DeepSeek-V2.
3. Pobieranie modelu
| Model | Łączna liczba parametrów | Aktywowane parametry | Długość kontekstu | |
|---|---|---|---|---|
| DeepSeek-V2-Lite | 16B | 2.4B | 32K | |
| DeepSeek-V2-Lite-Chat (SFT) | 16B | 2.4B | 32K | |
| DeepSeek-V2 | 236B | 21B | 128K | |
| DeepSeek-V2-Chat (RL) | 236B | 21B | 128K |
- Uwaga: Ze względu na ograniczenia HuggingFace, wersja open-source może działać wolniej na GPU w porównaniu do naszej wewnętrznej implementacji.
- Aby zoptymalizować wydajność modelu, oferujemy dedykowane rozwiązanie vLLM, które umożliwia bardziej efektywne uruchamianie modeli.
4. Wyniki ewaluacji
Model bazowy
Benchmark standardowy (Modele większe niż 67B)
| Benchmark | Dziedzina | LLaMA3 70B | Mixtral 8x22B | DeepSeek-V1 (Dense-67B) | DeepSeek-V2 (MoE-236B) |
|---|---|---|---|---|---|
| MMLU | Język angielski | 78.9 | 77.6 | 71.3 | 78.5 |
| BBH | Język angielski | 81.0 | 78.9 | 68.7 | 78.9 |
| C-Eval | Język chiński | 67.5 | 58.6 | 66.1 | 81.7 |
| CMMLU | Język chiński | 69.3 | 60.0 | 70.8 | 84.0 |
| HumanEval | Kodowanie | 48.2 | 53.1 | 45.1 | 48.8 |
| MBPP | Kodowanie | 68.6 | 64.2 | 57.4 | 66.6 |
| GSM8K | Matematyka | 83.0 | 80.3 | 63.4 | 79.2 |
| Math | Matematyka | 42.2 | 42.5 | 18.7 | 43.6 |
Benchmark standardowy (Modele mniejsze niż 16B)
| Benchmark | Dziedzina | DeepSeek 7B (Dense) | DeepSeekMoE 16B | DeepSeek-V2-Lite (MoE-16B) |
|---|---|---|---|---|
| Architektura | – | MHA+Dense | MHA+MoE | MLA+MoE |
| MMLU | Język angielski | 48.2 | 45.0 | 58.3 |
| BBH | Język angielski | 39.5 | 38.9 | 44.1 |
| C-Eval | Język chiński | 45.0 | 40.6 | 60.3 |
| CMMLU | Język chiński | 47.2 | 42.5 | 64.3 |
| HumanEval | Kodowanie | 26.2 | 26.8 | 29.9 |
| MBPP | Kodowanie | 39.0 | 39.2 | 43.2 |
| GSM8K | Matematyka | 17.4 | 18.8 | 41.1 |
| Math | Matematyka | 3.3 | 4.3 | 17.1 |
Aby uzyskać więcej szczegółów dotyczących ewaluacji, w tym ustawienia few-shot i użyte prompty, zapraszamy do zapoznania się z naszą publikacją
Okno kontekstowe

Wyniki ewaluacji w testach Needle In A Haystack (NIAH). DeepSeek-V2 osiąga wysoką skuteczność przy wszystkich długościach okna kontekstowego aż do 128K.
Ewaluacja modelu czatu
Benchmark standardowy (Modele większe niż 67B)
| Benchmark | Dziedzina | QWen1.5 72B Chat | Mixtral 8x22B | LLaMA3 70B Instruct | DeepSeek-V1 Chat (SFT) | DeepSeek-V2 Chat (SFT) | DeepSeek-V2 Chat (RL) |
|---|---|---|---|---|---|---|---|
| MMLU | Język angielski | 76.2 | 77.8 | 80.3 | 71.1 | 78.4 | 77.8 |
| BBH | Język angielski | 65.9 | 78.4 | 80.1 | 71.7 | 81.3 | 79.7 |
| C-Eval | Język chiński | 82.2 | 60.0 | 67.9 | 65.2 | 80.9 | 78.0 |
| CMMLU | Język chiński | 82.9 | 61.0 | 70.7 | 67.8 | 82.4 | 81.6 |
| HumanEval | Kodowanie | 68.9 | 75.0 | 76.2 | 73.8 | 76.8 | 81.1 |
| MBPP | Kodowanie | 52.2 | 64.4 | 69.8 | 61.4 | 70.4 | 72.0 |
| LiveCodeBench (0901-0401) | Kodowanie | 18.8 | 25.0 | 30.5 | 18.3 | 28.7 | 32.5 |
| GSM8K | Matematyka | 81.9 | 87.9 | 93.2 | 84.1 | 90.8 | 92.2 |
| Math | Matematyka | 40.6 | 49.8 | 48.5 | 32.6 | 52.7 | 53.9 |
Benchmark standardowy (Modele mniejsze niż 16B)
| Benchmark | Dziedzina | DeepSeek 7B Chat (SFT) | DeepSeekMoE 16B Chat (SFT) | DeepSeek-V2-Lite 16B Chat (SFT) |
|---|---|---|---|---|
| MMLU | Język angielski | 49.7 | 47.2 | 55.7 |
| BBH | Język angielski | 43.1 | 42.2 | 48.1 |
| C-Eval | Język chiński | 44.7 | 40.0 | 60.1 |
| CMMLU | Język chiński | 51.2 | 49.3 | 62.5 |
| HumanEval | Kodowanie | 45.1 | 45.7 | 57.3 |
| MBPP | Kodowanie | 39.0 | 46.2 | 45.8 |
| GSM8K | Matematyka | 62.6 | 62.2 | 72.0 |
| Math | Matematyka | 14.7 | 15.2 | 27.9 |
Ewaluacja generowania otwartego w języku angielskim
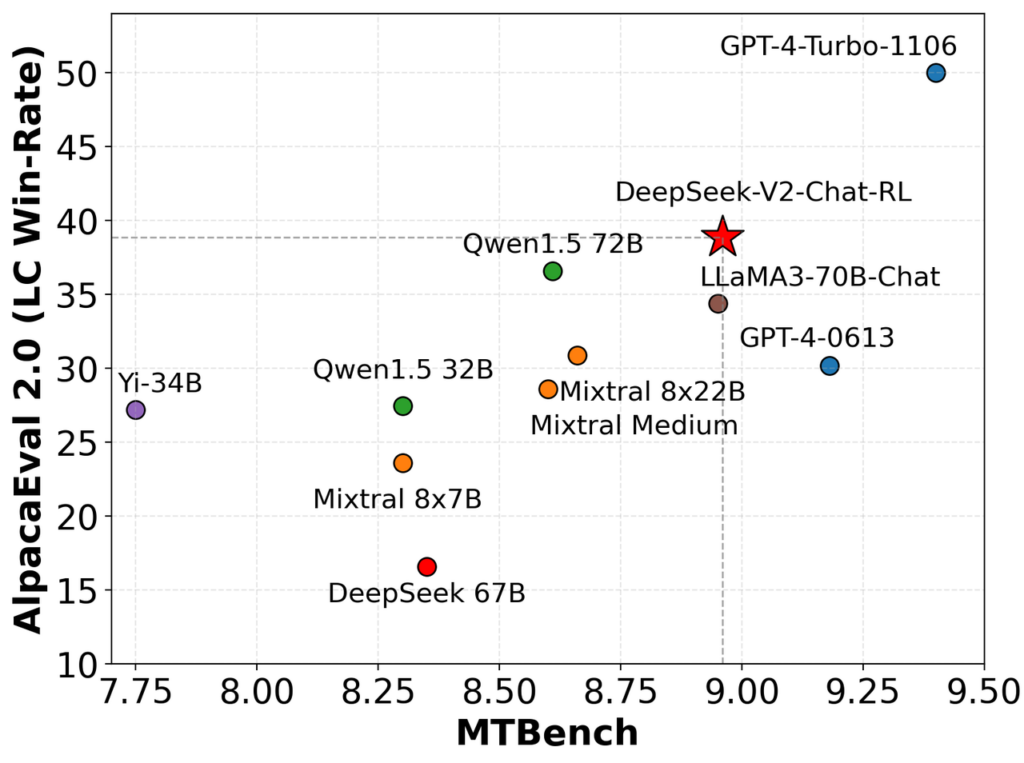
Przeprowadziliśmy ewaluację naszego modelu w testach AlpacaEval 2.0 oraz MTBench, wykazując konkurencyjną wydajność DeepSeek-V2-Chat-RL w generowaniu konwersacji w języku angielskim.
5. Architektura modelu
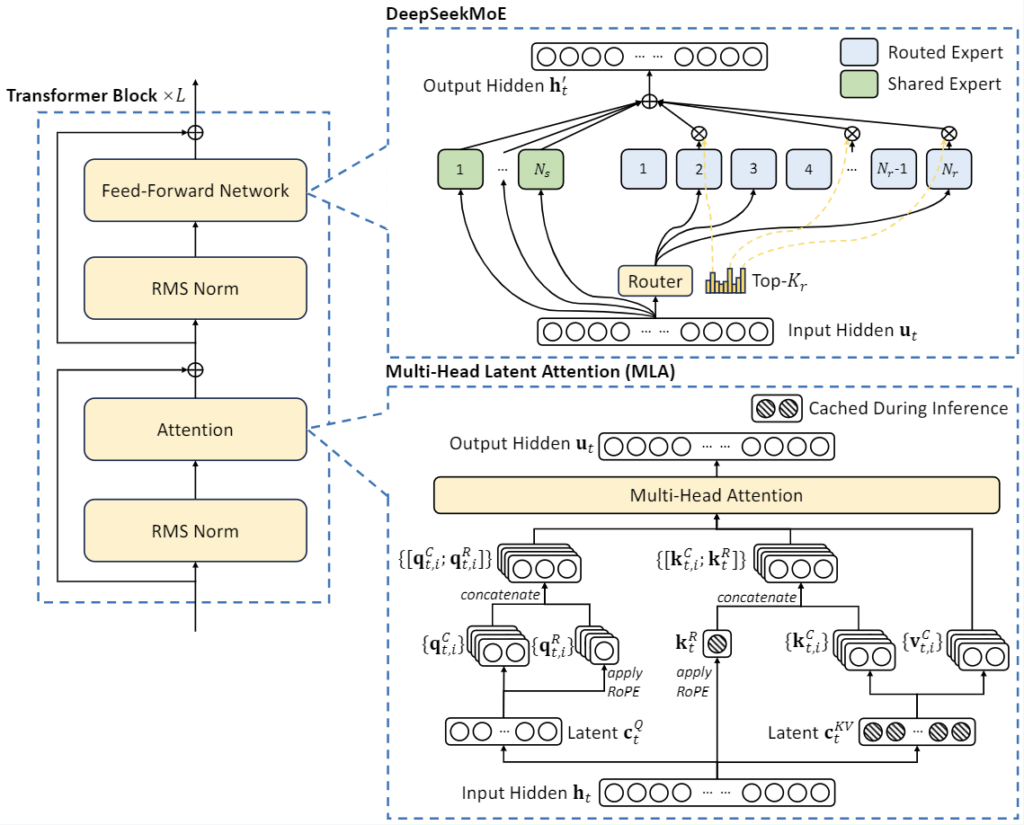
DeepSeek-V2 wykorzystuje innowacyjne rozwiązania architektoniczne, aby zapewnić ekonomiczne szkolenie i wydajne wnioskowanie:
-
Mechanizm uwagi (Attention):
Opracowaliśmy MLA (Multi-head Latent Attention), który wykorzystuje kompresję niskiego rzędu dla kluczy i wartości (low-rank key-value union compression), eliminując wąskie gardło związane z pamięcią podręczną key-value podczas wnioskowania. Dzięki temu model obsługuje bardziej efektywne generowanie odpowiedzi. -
Sieci Feed-Forward (FFN):
Zastosowaliśmy DeepSeekMoE, wysokowydajną architekturę Mixture-of-Experts (MoE), która umożliwia szkolenie silniejszych modeli przy niższych kosztach.
6. Witryna czatu
Możesz rozmawiać z DeepSeek-V2 na oficjalnej stronie deepseekpolsku.com