
1. Wprowadzenie
Przedstawiamy DeepSeek-V3, potężny model językowy oparty na architekturze Mixture-of-Experts (MoE), posiadający 671 miliardów parametrów, z których 37 miliardów jest aktywowanych dla każdego tokena. Aby zapewnić wydajne wnioskowanie i opłacalne szkolenie, DeepSeek-V3 wykorzystuje Multi-head Latent Attention (MLA) oraz DeepSeekMoE, technologie wcześniej gruntownie przetestowane w DeepSeek-V2.
Dodatkowo DeepSeek-V3 wprowadza strategię bez pomocniczej straty dla równoważenia obciążenia oraz stosuje cel treningowy oparty na przewidywaniu wielu tokenów, co przekłada się na wyższą wydajność modelu. Został on wstępnie przetrenowany na 14,8 bilionach zróżnicowanych i wysokiej jakości tokenów, a następnie poddany nadzorowanemu dostrajaniu (Supervised Fine-Tuning) oraz uczeniu ze wzmocnieniem (Reinforcement Learning), co pozwoliło w pełni wykorzystać jego potencjał.
Kompleksowe testy wykazały, że DeepSeek-V3 przewyższa inne modele open-source i osiąga wyniki porównywalne z czołowymi modelami zamkniętymi. Mimo swojej wysokiej wydajności pełne szkolenie modelu wymagało jedynie 2,788 miliona godzin pracy na GPU H800. Co więcej, cały proces treningowy przebiegł stabilnie – nie odnotowano żadnych krytycznych skoków utraty ani konieczności wycofywania postępów.
2. Podsumowanie Modelu
Architektura: Innowacyjna strategia równoważenia obciążenia i cel treningowy
Bazując na wydajnej architekturze DeepSeek-V2, wprowadziliśmy strategię równoważenia obciążenia bez pomocniczej straty, co minimalizuje spadek wydajności wynikający z wymuszania równomiernego podziału zasobów.
Dodatkowo, opracowaliśmy Multi-Token Prediction (MTP) jako nowy cel treningowy, który okazał się korzystny dla wydajności modelu. MTP może również zostać wykorzystany do spekulacyjnego dekodowania, co przyspiesza proces wnioskowania.
Wstępne trenowanie: Maksymalna efektywność szkolenia
Wprowadziliśmy ramy treningowe oparte na precyzji FP8, jako pierwsi testując skuteczność i efektywność tego podejścia na modelu o ekstremalnie dużej skali.
Dzięki współprojektowaniu algorytmów, frameworków i sprzętu przełamaliśmy wąskie gardło komunikacyjne w treningu MoE między węzłami, osiągając niemal pełne nakładanie się obliczeń i komunikacji.
To znacząco poprawiło wydajność treningu i zmniejszyło jego koszty, umożliwiając dalsze skalowanie modelu bez dodatkowego obciążenia.
Dzięki ekonomicznemu kosztowi jedynie 2,664 miliona godzin pracy na GPU H800, udało nam się przeprowadzić wstępne trenowanie DeepSeek-V3 na 14,8 bilionach tokenów, tworząc najmocniejszy obecnie otwartoźródłowy model bazowy. Kolejne etapy szkolenia po wstępnym trenowaniu wymagały zaledwie 0,1 miliona godzin pracy GPU.
Szkolenie końcowe: Destylacja wiedzy z DeepSeek-R1
Wprowadziliśmy innowacyjną metodologię destylacji zdolności rozumowania z modelu o długim Chain-of-Thought (CoT), a konkretnie jednego z modeli z serii DeepSeek-R1, do standardowych LLM-ów, w tym DeepSeek-V3.
Nasz proces integruje wzorce weryfikacji i refleksji z R1 w DeepSeek-V3, co znacząco poprawia jego zdolności rozumowania. Jednocześnie zachowaliśmy kontrolę nad stylem i długością generowanych odpowiedzi, zapewniając ich spójność i wysoką jakość.
3. Wyniki Ewaluacji
Porównanie modeli bazowych w standardowych benchmarkach
| Benchmark (Metryka) | Liczba strzałów | DeepSeek-V2 | Qwen2.5 72B | LLaMA3.1 405B | DeepSeek-V3 |
|---|---|---|---|---|---|
| Architektura | – | MoE | Dense | Dense | MoE |
| Aktywne Parametry | – | 21B | 72B | 405B | 37B |
| Łączna liczba parametrów | – | 236B | 72B | 405B | 671B |
| Język angielski | |||||
| Pile-test (BPB) | – | 0.606 | 0.638 | 0.542 | 0.548 |
| BBH (EM) | 3-shot | 78.8 | 79.8 | 82.9 | 87.5 |
| MMLU (Acc.) | 5-shot | 78.4 | 85.0 | 84.4 | 87.1 |
| MMLU-Redux (Acc.) | 5-shot | 75.6 | 83.2 | 81.3 | 86.2 |
| MMLU-Pro (Acc.) | 5-shot | 51.4 | 58.3 | 52.8 | 64.4 |
| DROP (F1) | 3-shot | 80.4 | 80.6 | 86.0 | 89.0 |
| ARC-Easy (Acc.) | 25-shot | 97.6 | 98.4 | 98.4 | 98.9 |
| ARC-Challenge (Acc.) | 25-shot | 92.2 | 94.5 | 95.3 | 95.3 |
| HellaSwag (Acc.) | 10-shot | 87.1 | 84.8 | 89.2 | 88.9 |
| PIQA (Acc.) | 0-shot | 83.9 | 82.6 | 85.9 | 84.7 |
| WinoGrande (Acc.) | 5-shot | 86.3 | 82.3 | 85.2 | 84.9 |
| RACE-Middle (Acc.) | 5-shot | 73.1 | 68.1 | 74.2 | 67.1 |
| RACE-High (Acc.) | 5-shot | 52.6 | 50.3 | 56.8 | 51.3 |
| TriviaQA (EM) | 5-shot | 80.0 | 71.9 | 82.7 | 82.9 |
| NaturalQuestions (EM) | 5-shot | 38.6 | 33.2 | 41.5 | 40.0 |
| AGIEval (Acc.) | 0-shot | 57.5 | 75.8 | 60.6 | 79.6 |
| Kodowanie | |||||
| HumanEval (Pass@1) | 0-shot | 43.3 | 53.0 | 54.9 | 65.2 |
| MBPP (Pass@1) | 3-shot | 65.0 | 72.6 | 68.4 | 75.4 |
| LiveCodeBench-Base (Pass@1) | 3-shot | 11.6 | 12.9 | 15.5 | 19.4 |
| CRUXEval-I (Acc.) | 2-shot | 52.5 | 59.1 | 58.5 | 67.3 |
| CRUXEval-O (Acc.) | 2-shot | 49.8 | 59.9 | 59.9 | 69.8 |
| Matematyka | |||||
| GSM8K (EM) | 8-shot | 81.6 | 88.3 | 83.5 | 89.3 |
| MATH (EM) | 4-shot | 43.4 | 54.4 | 49.0 | 61.6 |
| MGSM (EM) | 8-shot | 63.6 | 76.2 | 69.9 | 79.8 |
| CMath (EM) | 3-shot | 78.7 | 84.5 | 77.3 | 90.7 |
| Język chiński | |||||
| CLUWSC (EM) | 5-shot | 82.0 | 82.5 | 83.0 | 82.7 |
| C-Eval (Acc.) | 5-shot | 81.4 | 89.2 | 72.5 | 90.1 |
| CMMLU (Acc.) | 5-shot | 84.0 | 89.5 | 73.7 | 88.8 |
| CMRC (EM) | 1-shot | 77.4 | 75.8 | 76.0 | 76.3 |
| C3 (Acc.) | 0-shot | 77.4 | 76.7 | 79.7 | 78.6 |
| CCPM (Acc.) | 0-shot | 93.0 | 88.5 | 78.6 | 92.0 |
| Wielojęzyczność | |||||
| MMMLU-non-English (Acc.) | 5-shot | 64.0 | 74.8 | 73.8 | 79.4 |
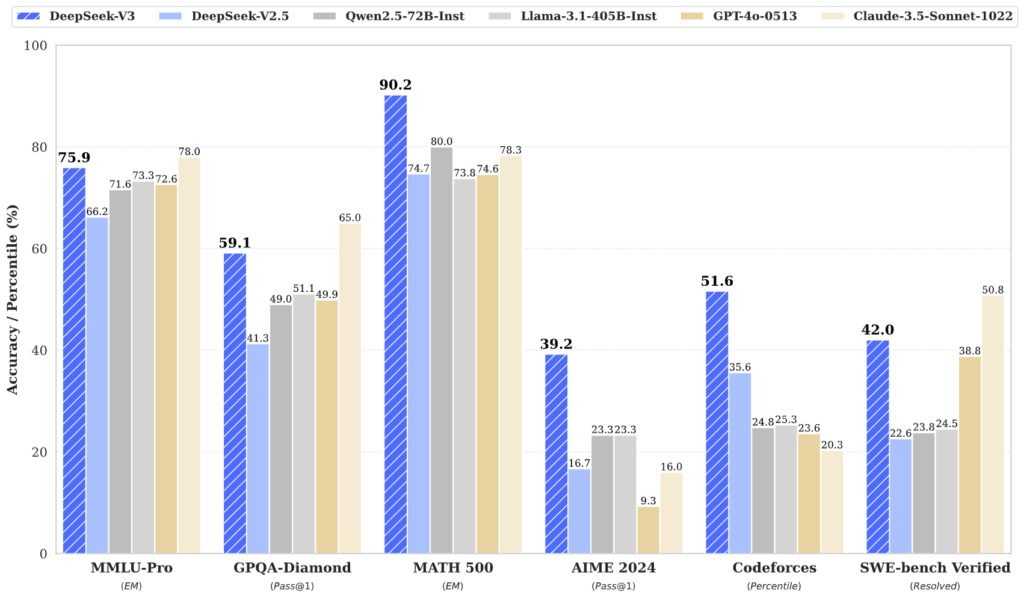
Wyniki ewaluacji modelu czatu
Porównanie modeli w standardowych benchmarkach (Modele większe niż 67B parametrów)
| Benchmark (Metryka) | DeepSeek V2-0506 | DeepSeek V2.5-0905 | Qwen2.5 72B-Inst. | Llama3.1 405B-Inst. | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 |
|---|---|---|---|---|---|---|---|
| Architektura | MoE | MoE | Dense | Dense | – | – | MoE |
| Aktywne Parametry | 21B | 21B | 72B | 405B | – | – | 37B |
| Łączna liczba parametrów | 236B | 236B | 72B | 405B | – | – | 671B |
| Język angielski | |||||||
| MMLU (EM) | 78.2 | 80.6 | 85.3 | 88.6 | 88.3 | 87.2 | 88.5 |
| MMLU-Redux (EM) | 77.9 | 80.3 | 85.6 | 86.2 | 88.9 | 88.0 | 89.1 |
| MMLU-Pro (EM) | 58.5 | 66.2 | 71.6 | 73.3 | 78.0 | 72.6 | 75.9 |
| DROP (3-shot F1) | 83.0 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | 91.6 |
| IF-Eval (Prompt Strict) | 57.7 | 80.6 | 84.1 | 86.0 | 86.5 | 84.3 | 86.1 |
| GPQA-Diamond (Pass@1) | 35.3 | 41.3 | 49.0 | 51.1 | 65.0 | 49.9 | 59.1 |
| SimpleQA (Correct) | 9.0 | 10.2 | 9.1 | 17.1 | 28.4 | 38.2 | 24.9 |
| FRAMES (Acc.) | 66.9 | 65.4 | 69.8 | 70.0 | 72.5 | 80.5 | 73.3 |
| LongBench v2 (Acc.) | 31.6 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | 48.7 |
| Kodowanie | |||||||
| HumanEval-Mul (Pass@1) | 69.3 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 | 82.6 |
| LiveCodeBench (Pass@1-COT) | 18.8 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | 40.5 |
| LiveCodeBench (Pass@1) | 20.3 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | 37.6 |
| Codeforces (Percentyl) | 17.5 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | 51.6 |
| SWE Verified (Resolved) | – | 22.6 | 23.8 | 24.5 | 50.8 | 38.8 | 42.0 |
| Aider-Edit (Acc.) | 60.3 | 71.6 | 65.4 | 63.9 | 84.2 | 72.9 | 79.7 |
| Aider-Polyglot (Acc.) | – | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | 49.6 |
| Matematyka | |||||||
| AIME 2024 (Pass@1) | 4.6 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 | 39.2 |
| MATH-500 (EM) | 56.3 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | 90.2 |
| CNMO 2024 (Pass@1) | 2.8 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | 43.2 |
| Język chiński | |||||||
| CLUEWSC (EM) | 89.9 | 90.4 | 91.4 | 84.7 | 85.4 | 87.9 | 90.9 |
| C-Eval (EM) | 78.6 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | 86.5 |
| C-SimpleQA (Correct) | 48.5 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 | 64.8 |
Ewaluacja generowania otwartego (Open-Ended Generation Evaluation)
| Model | Arena-Hard | AlpacaEval 2.0 |
|---|---|---|
| DeepSeek-V2.5-0905 | 76.2 | 50.5 |
| Qwen2.5-72B-Instruct | 81.2 | 49.1 |
| LLaMA-3.1 405B | 69.3 | 40.5 |
| GPT-4o-0513 | 80.4 | 51.1 |
| Claude-Sonnet-3.5-1022 | 85.2 | 52.0 |
| DeepSeek-V3 | 85.5 | 70.0 |
5. Strona czatu i platforma API
| Usługa | Adres |
|---|---|
| Czat z DeepSeek-V3 | deepseekpolsku.com |
| API kompatybilne z OpenAI | https://deepseekpolsku.com/ |